精准变量理解
Python_协程
协程本身的定义,与进程、线程其实差不多,都是用于控制过程的工具:
Python_切片原理
切片是Python重要的特性之一.与切片密切相关的是索引.一般情况下索引的返回值是序列的元素,切片的返回值是序列:
Python_上下文管理器
上下文处理器是用来管理with语句.与之对标的概念就是迭代器用来管理for语句.
Python_python2的编码问题
最近在调试python2过程中经常出现编码的问题,尤其是将python3程序重构为python2程序过程中出现的问题。
问题一:编码本身有什么不同
- 这在字符编码.md文件中已经有了清晰的解释
问题二:python2处理中文时为什么总是会出现乱码
- encode与decode两者需要明确区分
- 对应的字符与字节也需要区分
带着以上两个问题看到了相关的解释,特记录如下:
字符与字节问题
字符与字节之间并不是同等地位。
字符串:由字符组成的序列
字符:字符是人使用的符号,是一种人所认知的单位。例如:“中” , “1” ,“¥”等等
在python3中,str对象中获取的元素是Unicode字符
在python2中,str对象中获取的原始字节序列
可以看到同样是str对象,python2中其实是字节,python3中是字符
字节:字节是计算机所使用的符号,是8位的二进制数字。例如 0x01,01010101,0b45
不同编码体制中,字符与字节拥有着不同的对应关系:
ASCII码: 一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。一个二进制数字序列,在计算机中作为一个数字单元,一般为8位二进制数,换算为十进制。最小值0,最大值255。
UTF-8:一个英文字符=一个字节,一个中文(含繁体)=三个字节。
已知UTF-8编码是UNICODE编码的实现形式的一种,Unicode规定了世界上所有的符号与二进制的对应关系,但是其实现形式多种多样,比如UTF-8,UTF-16等等。
Unicode才是真正的(人)字符串,而用ASCII、UTF-8、GBK等字符编码表示的是字节串。
从这个角度理解unicode就是CAMEO,utf-8就是VerbDic.
encode与decode
encode与decode分别对应
encode: 将人类可识别的字符转换为机器可识别的字节码,字符到字节的过程。
decode:**就是将机器可识别的字节码转换成人类可识别的字符,字节到字符的过程**。
python中的默认编码
Python源代码的执行过程
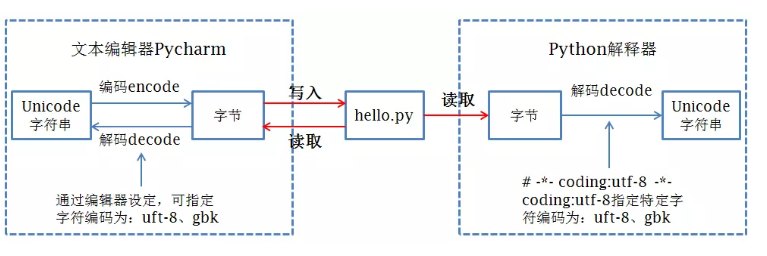
我们都知道,磁盘上的文件都是以二进制格式存放的,其中文本文件都是以某种特定编码的字节形式存放的。对于程序源代码文件的字符编码是由编辑器指定的,比如我们使用Pycharm来编写Python程序时会指定工程编码和文件编码为UTF-8,那么Python代码被保存到磁盘时就会被转换为UTF-8编码对应的字节(encode过程)后写入磁盘。
当执行Python代码文件中的代码时,Python解释器在读取Python代码文件中的字节串之后,需要将其转换为Unicode字符串(decode过程)之后才执行后续操作。
默认编码
如果我们没有在代码文件指定字符编码,Python解释器会使用哪种字符编码把从代码文件中读取到的字节转换为Unicode字符串呢?就像我们配置某些软件时,有很多默认选项一样,需要在Python解释器内部设置默认的字符编码来解决这个问题,这就是“默认编码”。
Python2和Python3的解释器使用的默认编码是不一样的,我们可以通过sys.getdefaultencoding()来获取默认编码:
- Python2:ascii
- Python3:utf-8
python2与python3处理文件
对于Python2来讲,Python解释器在读取到中文字符的字节码时,会先查看当前代码文件头部是否指明字符编码是什么。如果没有指定,则使用默认字符编码”ASCII”进行解码,导致中文字符解码失败,出现如下错误
2
see http://python.org/dev/peps/pep-0263/ for details对于Python3来讲,执行过程是一样的,只是Python3的解释器以”UTF-8”作为默认编码,但是这并不表示可以完全兼容中文问题。比如我们在Windows上进行开发时,Python工程及代码文件都使用的是默认的GBK编码,也就是说Python代码文件是被转换成GBK格式的字节码保存到磁盘中的。Python3的解释器执行该代码文件时,试图用UTF-8进行解码操作时,同样会解码失败,出现如下错误:
2
see http://python.org/dev/peps/pep-0263/ for details
Python2 Python3对字符串的支持
Python2
Python2中对字符串的支持由以下三个类别提供:
2
3
class str(basestring)
class unicode(basestring)其中basestring类是str类与unicode类的父类。
str其实是字节串,它是unicode经过编码后的字节组成的序列。
对UTF-8编码的str’汉’使用len()函数时,结果是3,因为UTF-8编码的’汉’==’\xE6\xB1\x89’。
unicode才是真正意义上的字符串,对字节串str使用正确的字符编码进行解码后获得,并且len(u’汉’)==1。
Python3
Python3中对字符串的支持进行了实现类层次的上简化,去掉了unicode类,添加了一个bytes类。从表面上来看,可认为Python3中的str和unicode合二为一了。
2
class str(object)实际上,Python3中已经意识到之前的错误,开始明确区分字符串与字节。
因此Python3中的str已经是真正的字符串,而字节是用单独的bytes类来表示。
也就是说,Python3默认定义的就是字符串,实现了对Unicode的内置支持,减轻了程序员对字符串处理的负担。
2
3
4
5
6
7
8
#-*- coding:utf-8 -*-
a = '你好'
b = u'你好'
c = '你好'.encode('gbk')
print(type(a),len(a)) # output:<class'str'> 2
print(type(b),len(b)) # output:<class'str'> 2
print(type(c),len(c)) # output:<class'bytes'> 4
字符与字节转换
4.3的名称我自己起的,合不合适的我们再看
单个字符的encode:
Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
1
2
3
4
5
6
7
8>>> ord('A')
65
>>> ord('中')
20013
>>> chr(97)
'a'
>>> chr(20013)
'中'如果知道字符的整数编码,还可以用十六进制这么写字符:
1
2>>> '\u4e2d\u6587'
'中文'字符.encode() = 字节
Python3的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:x = b’ABC’。
要注意区分’ABC’和b’ABC’,前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
1
2
3
4
5
6
7
8>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)常见的中文报错问题愿意:
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
字节.decode() = 字符:
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
1
2
3
4>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'要计算str包含多少个字符,可以用len()函数:
1
2
3
4>>> len('ABC')
3
>>> len('中文')
2len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
1
2
3
4
5
6>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6Python2 Python3字符编码的转换
Unicode字符串可以与任意字符编码的字节串进行相互转换:
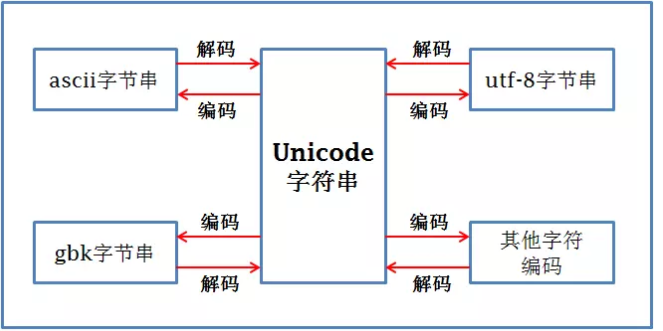
从上图可以看出不同字节编码之间是可以通过Unicode来实现相互转换的。
Python2中的字符串进行字符编码转换过程是:
字节串(Python2的str默认是字节串)–>decode(‘原来的字符编码’)–>Unicode字符串–>encode(‘新的字符编码’)–>字节串
2
3
4
5
6
#-*- coding:utf-8 -*-
utf_8_a = '我爱中国'
gbk_a = utf_8_a.decode('utf-8').encode('gbk')
print(gbk_a.decode('gbk'))
# 输出结果:我爱中国
Python3中定义的字符串默认就是unicode,因此不需要先解码,可以直接编码成新的字符编码:
字符串(str就是Unicode字符串)–>encode(‘新的字符编码’)–>字节串
2
3
4
5
6
#-*- coding:utf-8 -*-
utf_8_b = '我爱中国'
gbk_b = utf_8_b.encode('gbk')
print(gbk_b.decode('gbk'))
# 输出结果:我爱中国
Python2 中乱码问题的解决方案
不要相信Print()结果
print()函数本身是加工后给人看的,不管给它什么样子的编码格式文件,都可以打印出来。
这也就意味着print(),并没有展示变量的本质。
可以选择 jupyter中
这里是Python2
2
3
chinese
'\xe4\xb8\xad\xe6\x96\x87'
Python2中“字符串”两大阵容
unicode和str
如果
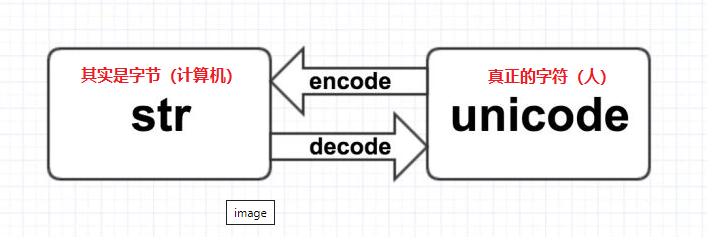
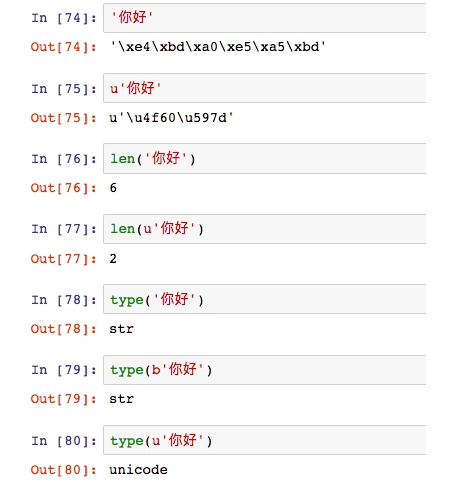
type(字符串)显示结果是str,其实指的是bytes字节码。由上面的内容我们已经理解当前python2中str对象与unicode对象分别代表:字节与字符
encoding与decoding
从
unicode转换到str,这个叫encoding,编码。
从str转换到unicode,这个叫decoding,解码。
案例
Python2
具体统一方案
见剩余内容https://segmentfault.com/a/1190000013202801
这里的统一方案无非就是按照字符处理文件还是按照字节处理文件,何时进行decode何时encode的问题。
做个给出了一个方案,但我目前并没有采用,这里不详细写
Python_python Call Graph学习
Python Call Graph是用于可视化Python内部函数调用的包,其生成的为动态程序调用图。
Python_heapq类
Python官方提供的最小堆类:
Python_else块
else简单也不简单:
Python_dict与set
Python中的字典类与集合类其内部均采用散列表实现,查询速度不受规模影响。
Python_del与弱引用
相似概念