堆排序实在数据结构中常见的排序算法,但许久未看已经忘得差不多啦。这里简单的将相关概念记录如下:
什么是堆
堆是利用完全二叉树的结构进行维护的一位数组,我们可以将其看作是一维数组也可以看作是完全二叉树,物理上是线性结构,理论上是非线性结构。
大顶堆:每个节点值大于或等于左右子节点的值
小顶堆:每个节点值小于或等于左右子节点的值
这也是堆最重要的特性
举个例子
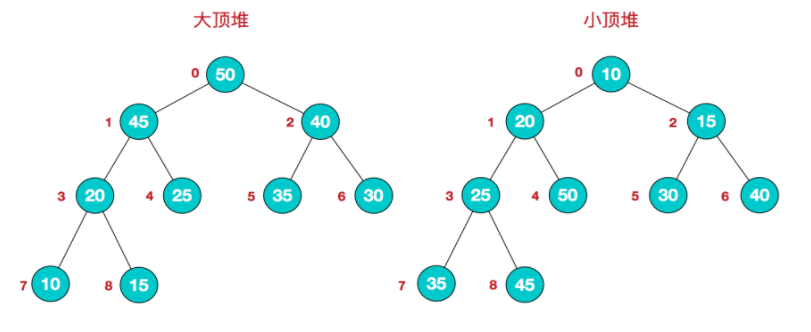
我们对堆中的结点按层进行编号,将这种逻辑结构映射到数组中就是下面这个样子.
公式定义:
大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
相关易混淆概念
平衡树:比如AVL、红黑树等,其要求左子树节点<根<右子树节点,并且左右子树均符合此定义。也就是说其整棵树都是有序的。
为什么不用树存储而使用数组:1.树存储本身浪费空间 2.堆逻辑上为完全二叉树,这对于数组而言不浪费空间。
堆不适合搜索:虽然二叉树是适合搜索的,但是堆并不合适,这也是堆部分有序造成的困扰。
堆排序
堆排序是堆最常见的应用方式,堆排序的过程由三个步骤迭代完成。
堆的构建
初始堆的构建,是堆所有的非叶子节点进行调整,时间复杂度为$ O(n) $,自下而上
出堆
堆调整
堆调整只需要更改部分节点变化的节点即可,时间复杂度为$ O(log(n)) $ ,是自上而下的
升序 : 使用大顶堆
每个结点的值都大于或等于其左右孩子结点的值,我们把大顶堆构建完毕后根节点的值一定是最大的,然后把根节点的和最后一个元素(也可以说最后一个节点)交换位置,那么末尾元素此时就是最大元素了(理解这点很重要)
- 先n个元素的无序序列,构建成大顶堆
- 将根节点与最后一个元素交换位置,(将最大元素”沉”到数组末端)
- 交换过后可能不再满足大顶堆的条件,所以需要将剩下的n-1个元素重新构建成大顶堆
- 重复第二步、第三步直到整个数组排序完成
降序 :使用小顶堆
代码示例
代码中展示了通过一个大顶堆,构建升序的过程,具体的展示可以见 排序算法总结.md,gif图生动的展示了过程.
1 | # 构建大顶堆的节点交换函数,作为辅助函数 |

