关于Python2与3的编码差异、unicode的概念、encode与Decode的问题都在Python2编码问题已经讨论过。这里讨论的是
编码相关的问题
问题是怎么产生的?
日常应用中在解码与编码过程中经常会报错,而报错的原因多半是由于以当前给定的编码方式无法正确解码。这说明不同的编码机制只能对一部分字符进行编码,当你采用其他编码算法进行解码时,那么则无法适配。如图所示:
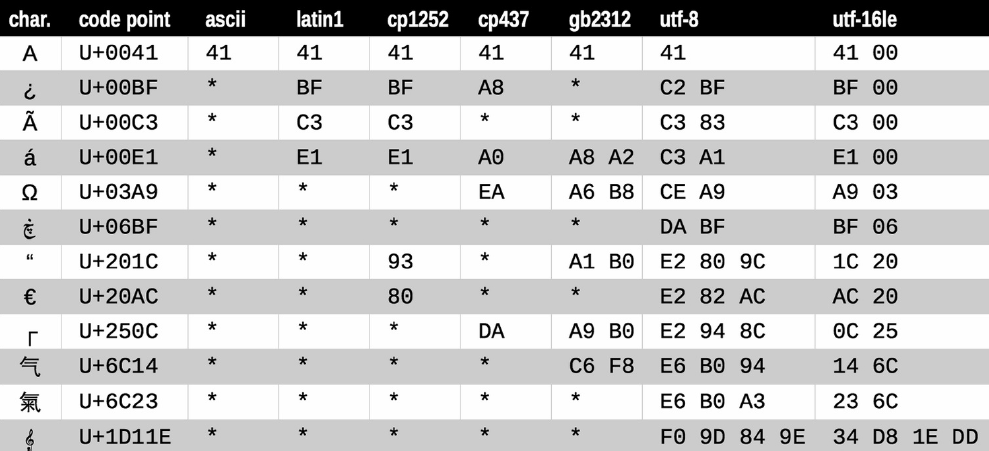
在上图中不同的字符,存在部分编码机制没法编码。而在使用中往往出现有三种编码机制:ascII,gbk,utf-8这三种。
了解解码问题
UnicodeEncodeError
多数非UTF编码器只能处理Unicode字符的小部分子集。将文本转换为字节序列时,如果目标编码中没有定义某个字符,就会抛出UnicdeEncodeError异常,除非把errors参数传递给编码方法或函数,对错误进行特殊处理。

上面的代码中展示了3中cp437编码算法无法处理此字符。可通过errors关键字对错误进行相关处理,而不抛出异常。
- ignore:跳过无法编码的字符,并不推荐使用
- replace:将无法编码的字符替换为?;数据出现损坏,用户知道
- xmlcharrefreplace:无法编码的字符替换为xml实体
UnicodeDecodeError
将字节转换为字符过程中出错,会抛出此异常。

SyntaxError
如何确定当前的编码
不能,除非有人告诉你。但是每种编码有自己的特点,统一字符编码侦测包 Chardet(https://pypi.python.org/pypi/chardet)就是这样工作的,它能识别所支持的 30 种编码。Chardet 是一个 Python 库,可以在程序中使用,不过它也提供了
命令行工具 chardetect。下面是它对本章书稿文件的检测报告:

处理文本文件的建议
存在一个三明治逻辑,将中间的肉比喻为业务的核心逻辑,将上面包比喻为字节转换为字符的过程,将下面包比喻为将字符转换为字节的过程。建议就是将上面包尽可能的早,而下面包尽可能的晚。

